Amgix Benchmarks: Database Backends
In this report we'll look at how hybrid search performs across three diverse BEIR datasets: SciFact (scientific claims), ArguAna (arguments and counterarguments), and TREC-COVID (medical research) on three different database backends: Qdrant, MariaDB, and PostgreSQL. We will focus mostly on the latency of the search queries, but will provide nDCG@101 scores for relevance.
Jump To Results
BEIR Benchmark Context
The BEIR (Benchmarking IR) benchmark suite2 provides standardized datasets for evaluating information retrieval systems. For context, BM25 baseline scores from the BEIR leaderboard are:
| Dataset | Documents | Queries | BM25 Baseline nDCG@10 |
|---|---|---|---|
| SciFact | 5,183 | 300 | 0.665 |
| ArguAna | 8,674 | 1,406 | 0.414 |
| TREC-COVID | 171,332 | 50 | 0.656 |
Note on methodology: All results in this report reflect single-stage retrieval without re-ranking. Many top-performing systems on the BEIR leaderboard use two-stage retrieval (initial retrieval + re-ranking), which can improve quality at the cost of additional latency. Our focus here is on comparing backend behavior under production-style search workloads that balance relevance with predictable response times. Query latency was measured client-side with 4 parallel workers, and includes the full Amgix request path: API call, query vector generation inside Amgix, distributed search, score fusion, and response. These are not raw database timings or "bring your own vectors" timings; they are end-to-end timings through the full system. Because model loading can dominate first-query latency, the reported P50 and P95 numbers should be read as warm, steady-state query latency rather than cold-start latency.
Limitations and tuning disclaimer
These SQL results reflect our configuration, not the theoretical limits of PostgreSQL or MariaDB. We are not database‑tuning experts; all databases ran in containers with minimal, pragmatic settings (hardly a production setup). It’s likely there are engine/configuration/indexing parameters, memory/IO layouts, or query planner settings that could materially improve SQL performance at scale. Our intent here is to report what we observed with reasonable defaults, not to claim an upper bound for these systems.
Test Setup
Hardware
Because we will be measuring latency, it's important to mention the hardware we used for the tests. All tests are performed on a single bare-metal machine with the following specifications:
- CPU: AMD Ryzen™ 9 5900X × 12 cores (24 threads)
- RAM: 64GB
- GPU: NVIDIA GeForce RTX 5060 Ti (16GB)
- Storage: SSD
- OS: Ubuntu 24.04.4 LTS
Amgix Deployment
Amgix v1.0.0-beta4 was deployed in Docker containers with a single Amgix API container and four (4) Amgix Encoder containers. We used a four-Encoder setup both to speed up the benchmark runs and to better reflect a production-style distributed deployment, where the system is scaled to handle concurrent queries. In these tests, clients send plain-text queries to the API; Amgix then distributes the query-processing work across the Encoder containers rather than expecting precomputed query vectors from the caller.
Amgix Encoder nodes are using GPU variants of the images, so dense embedding generation is GPU-accelerated. Since all instances are on the same physical machine, they all share the same single GPU.
RabbitMQ
RabbitMQ v4.1.3 is deployed in a single container with all default settings.
Backend Databases
All three databases will also run in Docker containers on the same physical machine. They are deployed with the following configurations:
- Qdrant:
- Version: 1.17.0
- All default settings
- MariaDB:
- Version: 11.8
- innodb_buffer_pool_size=4G
- innodb_buffer_pool_instances=4
- PostgreSQL:
- Version: 18.0
- effective_cache_size = 4GB
- shared_buffers = 1GB
- work_mem = 256MB
- maintenance_work_mem = 512MB
Vector Configurations
The hybrid collection is set up to use 3 vectors: WMTR (name and content), and dense on the content field only. Because the current version of MariaDB only supports one dense vector per table/collection, we are using the dense vector for the content field only across all backends to keep parity.
[
{"name": "wmtr", "type": "wmtr", "index_fields": ["name","content"]},
{"name": "dense", "type": "dense_model", "model": "sentence-transformers/all-MiniLM-L6-v2", "index_fields": ["content"]},
]
For information on WMTR see Amgix Benchmarks
For dense model vectors we simply chose a common small model: sentence-transformers/all-MiniLM-L6-v2.
Weight Tuning
We've used tuned weights from Amgix Benchmarks for the search queries. There are some differences in how vector search is implemented across backends, so if we wanted to optimize purely for relevance, we would re-run the tuning process on each dataset for each backend. However, the focus of this report is on latency, so we use the weights from the hybrid benchmark report as a reasonable approximation.
Amgix Search Query Flow
 Before we get to the results, let's take a look at the search query flow through Amgix. Every query goes through the following process:
Before we get to the results, let's take a look at the search query flow through Amgix. Every query goes through the following process:
- Query text and vector weights are sent to Amgix API.
- The API dispatches query-processing work to Amgix Encoders over RabbitMQ.
- Amgix Encoders generate query vectors inside the system.
- Encoders use the generated vectors to search the database collection, matching against the indexed vectors: WMTR on
nameandcontent, and/or dense oncontent. - Database search results are then ranked and fused using vector weights.
- Top 100 documents are returned to the caller.
Latency Measurements
For all latencies reported below, each workload was run three (3) times and we report the slowest observed result. Run-to-run differences were small, so this conservative choice does not materially change the overall conclusions.
SciFact Dataset
The SciFact dataset contains 5,183 documents and 300 queries focused on scientific claims and evidence verification. This makes it an ideal benchmark for evaluating search performance on domain-specific scientific content.
Results
| WMTR | Dense | Hybrid | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Qdrant | MariaDB | PostgreSQL | Qdrant | MariaDB | PostgreSQL | Qdrant | MariaDB | PostgreSQL | |
| nDCG@101 | 0.6611 | 0.6753 | 0.6753 | 0.6402 | 0.6402 | 0.6402 | 0.7157 | 0.7268 | 0.7269 |
| P50 (ms)3 | 23 | 21 | 20 | 24 | 36 | 19 | 35 | 38 | 26 |
| P95 (ms)4 | 30 | 31 | 26 | 30 | 54 | 25 | 45 | 49 | 33 |
Notes
- WMTR tests search with two (2) WMTR vectors (
nameandcontent). - Dense search is a single vector search using dense vector.
- Hybrid search is performed with all three (3) vectors.
Analysis
On the relatively small SciFact corpus (5,183 documents), all three backends land in essentially the same latency tier. Hybrid search P50 ranges from 26ms to 38ms, and P95 ranges from 33ms to 49ms. At that level, the differences feel more like normal environmental noise and timing fluctuation than a meaningful product distinction, especially given that we report the slowest observed result out of three runs.
Relevance is also very close across backends. On WMTR, MariaDB and PostgreSQL slightly outperform Qdrant (0.6753 vs 0.6611 nDCG@10). On Dense, the scores are effectively identical (0.6402 on all three backends). On Hybrid, SQL backends again come out a bit ahead, with 0.7268 / 0.7269 for MariaDB/PostgreSQL versus 0.7157 for Qdrant. These are small differences, but they show that on a dataset of this size, SQL backends are fully competitive on relevance.
The practical takeaway is that SciFact is too small for backend latency differences to matter much. All three systems are comfortably fast, and the choice of backend at this scale is better driven by operational preferences, existing infrastructure, and deployment simplicity than by raw query speed.
ArguAna Dataset
The ArguAna dataset contains 8,674 documents and 1,406 queries involving arguments and counterarguments. This dataset is particularly challenging as it requires understanding semantic relationships between opposing viewpoints expressed in natural language.
Results
| WMTR | Dense | Hybrid | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Qdrant | MariaDB | PostgreSQL | Qdrant | MariaDB | PostgreSQL | Qdrant | MariaDB | PostgreSQL | |
| nDCG@101 | 0.4694 | 0.4680 | 0.4639 | 0.5047 | 0.5030 | 0.5022 | 0.5348 | 0.5298 | 0.5270 |
| P50 (ms)3 | 22 | 41 | 34 | 24 | 39 | 19 | 35 | 50 | 41 |
| P95 (ms)4 | 29 | 57 | 44 | 30 | 55 | 25 | 45 | 67 | 53 |
Notes
- WMTR tests search with two (2) WMTR vectors (
nameandcontent). - Dense search is a single vector search using dense vector.
- Hybrid search is performed with all three (3) vectors.
Analysis
ArguAna is still a relatively small corpus, but unlike SciFact the latency differences no longer feel like pure noise. Qdrant remains the fastest overall, but the gap is still modest in absolute terms. For hybrid search, P50 ranges from 35ms on Qdrant to 50ms on MariaDB, while PostgreSQL lands in between at 41ms. P95 shows the same pattern, with 45ms on Qdrant, 53ms on PostgreSQL, and 67ms on MariaDB. All three remain comfortably within an interactive latency range.
Relevance differences are again small. On WMTR, Qdrant is slightly ahead (0.4694) with MariaDB (0.4680) close behind and PostgreSQL (0.4639) just a bit lower. On Dense, the three backends are nearly indistinguishable (0.5047, 0.5030, 0.5022). On Hybrid, Qdrant leads by a narrow margin at 0.5348, with MariaDB at 0.5298 and PostgreSQL at 0.5270. These gaps are measurable, but not large enough to outweigh operational considerations for many deployments.
The practical takeaway for ArguAna is that backend differences start to become visible, but not dramatic. Qdrant has a clear latency advantage, while MariaDB and PostgreSQL remain close enough that they still look viable for small to medium collections. At this scale, the decision is less about whether SQL can keep up at all, and more about whether the extra speed of a specialized vector backend is worth adding another system to the stack.
TREC-COVID Dataset
The TREC-COVID dataset contains 171,332 documents and 50 queries related to COVID-19 research articles. Despite having fewer queries, this dataset's large corpus size and specialized medical terminology make it an excellent test of search performance at scale.
Results
| WMTR | Dense | Hybrid | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Qdrant | MariaDB | PostgreSQL | Qdrant | MariaDB | PostgreSQL | Qdrant | MariaDB | PostgreSQL | |
| nDCG@101 | 0.6336 | 0.6318 | 0.6318 | 0.5870 | 0.5825 | 0.5846 | 0.6744 | 0.6679 | 0.6684 |
| P50 (ms)3 | 26 | 199 | 168 | 25 | 61 | 20 | 39 | 198 | 175 |
| P95 (ms)4 | 35 | 303 | 254 | 49 | 122 | 30 | 49 | 288 | 259 |
Notes
- WMTR tests search with two (2) WMTR vectors (
nameandcontent). - Dense search is a single vector search using dense vector.
- Hybrid search is performed with all three (3) vectors.
Analysis
TREC-COVID is where the backend differences become clearly meaningful. At 171,332 documents, Qdrant preserves essentially the same latency profile it had on the much smaller datasets, with hybrid search at 39ms P50 and 49ms P95. MariaDB and PostgreSQL are noticeably slower, landing around 198ms / 288ms and 175ms / 259ms respectively for hybrid search. That is a clear gap, but both SQL backends still remain within a latency range that is usable for many search workloads.
What stands out most is that SQL performance degrades, but not catastrophically. Even at this corpus size, hybrid search on PostgreSQL still stays under 200ms P50, and both SQL backends remain under 300ms P95 in these tests. That makes them meaningfully slower than Qdrant, but still fast enough to be realistic for many non-typeahead search workloads. The median numbers in particular are better than one might expect from a general-purpose relational database handling hybrid search over a large sparse index.
The main source of the latency gap here is not dense vector search by itself, but the sparse side of hybrid search. Qdrant's architecture is optimized around vector retrieval, while SQL backends have to do more work to execute sparse ranking over large posting lists. That difference becomes much more visible once the collection grows into the hundreds of thousands of documents.
Relevance remains tightly grouped across all three backends. On WMTR, Qdrant is slightly ahead at 0.6336, while MariaDB and PostgreSQL are tied at 0.6318. On Dense, Qdrant again leads, but only narrowly (0.5870 vs 0.5825 / 0.5846). On Hybrid, the same pattern holds: 0.6744 for Qdrant, 0.6679 for MariaDB, and 0.6684 for PostgreSQL. In other words, the main trade-off at this scale is latency, not search quality.
The practical takeaway is that Qdrant's advantage becomes real and consistent once the collection grows into the hundreds of thousands of documents. If you want the best latency with the least tuning, Qdrant is clearly the strongest backend here. At the same time, these results also show that SQL backends remain more viable than one might assume: with the current implementation, they are slower, but still entirely usable for many production-style search scenarios.
Summary
Hybrid search P503 latency (ms) by dataset and backend:
| SciFact P50 (ms) | ArguAna P50 (ms) | TREC-COVID P50 (ms) | |
|---|---|---|---|
| Qdrant | 35 | 35 | 39 |
| MariaDB | 38 | 50 | 198 |
| PostgreSQL | 26 | 41 | 175 |
Are SQL Backends Usable at Scale?
We wanted to see what happens with WMTR two (2) vectors search on SQL backends with larger collections. We ran WMTR-only tests on a PostgreSQL database using various subsets of the NQ (Natural Questions) BEIR dataset. For each test, a number of documents were picked at random from the larger dataset and 500 random queries were executed against the data.
Results
| Documents | PostgreSQL (P50) | PostgreSQL (P95) |
|---|---|---|
| 10,000 | 25 | 43 |
| 50,000 | 45 | 69 |
| 100,000 | 60 | 93 |
| 200,000 | 116 | 200 |
| 300,000 | 156 | 269 |
| 500,000 | 260 | 453 |
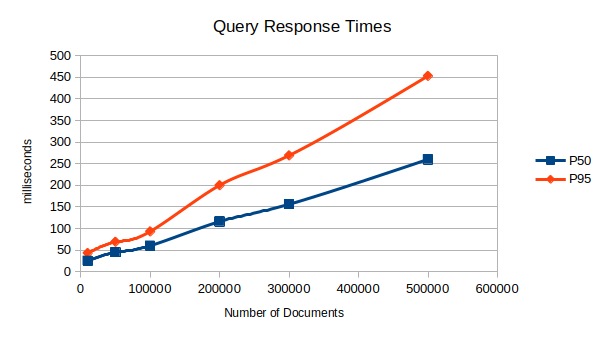
Analysis:
These results show that PostgreSQL latency with WMTR-only search increases as the collection grows, but the growth is not explosive. P50 rises from 25ms at 10,000 documents to 260ms at 500,000, while P95 rises from 43ms to 453ms over the same range. The curve clearly trends upward, but it looks much closer to linear than exponential.
What is especially notable is that the median stays relatively well-behaved even at larger scales. At 500,000 documents, PostgreSQL still delivers 260ms P50, which is slower than a specialized vector database but still reasonable for many interactive search workloads. The tail grows faster than the median, which is what we would expect as larger collections produce more expensive sparse query paths and more variance between easy and hard queries.
It is also important to keep in mind that this is a WMTR-only test. In other words, it isolates the scaling behavior of the sparse side of the system rather than the full hybrid search pipeline. That makes the trend particularly useful: it shows that SQL backends are not inherently collapsing under larger sparse indexes, even when working with a higher-dimensional sparse representation like WMTR.
Practical Implications:
For teams already using PostgreSQL, these numbers suggest that SQL remains a realistic option well into the hundreds of thousands of documents, especially if sub-300ms median latency is acceptable. PostgreSQL is clearly not matching Qdrant on absolute speed, but it is also not behaving in a way that would rule it out for production search by default.
The main caveat is tail latency. By 500,000 documents, P95 reaches 453ms, which means the slowest queries are becoming much more noticeable than the median. In practice, this suggests a fairly simple rule of thumb: PostgreSQL can remain viable at larger scales, but as collections grow, you need to pay increasing attention to the tail rather than just the average or median.
The broader takeaway is that SQL backends do not hit an immediate wall at scale. Their behavior is more gradual: latency increases with corpus size, tails widen, and eventually the trade-off may favor a specialized backend. But the transition is much less abrupt than one might assume.
Key Takeaways for SQL Backends
The benchmark results show that SQL backends remain far more competitive than one might assume. Across all three datasets, MariaDB and PostgreSQL stay close to Qdrant on relevance, and on the smaller SciFact and ArguAna corpora their latency remains in the same general interactive range. The biggest performance separation appears only once the collection grows into the hundreds of thousands of documents.
At larger scale, the main gap is on the sparse side of hybrid search rather than on dense vector retrieval by itself. Qdrant keeps a stronger latency profile as collections grow, while SQL backends pay a higher cost for sparse ranking over larger posting lists. Even so, the PostgreSQL scaling numbers show that this cost rises gradually rather than explosively, which makes SQL a viable option for many production search workloads.
Conclusion
Relevance Consistency
All three backends remain close on relevance across the tested datasets, even when using weights tuned on Qdrant. In practice, this means backend choice is driven much more by latency, operational constraints, and deployment preferences than by any large difference in search quality. Weight tuning on one backend also appears to transfer reasonably well to the others, at least as a starting point.
Practical Recommendations
Choose Qdrant when: - Lowest latency is a top priority - You expect to scale into the hundreds of thousands of documents and beyond - You want the most predictable latency across different dataset sizes - You can add a specialized database to your infrastructure
Choose a SQL backend when: - You want to avoid adding another database to your stack - You have a modest dataset or can accept higher latencies on larger collections - Your workload can tolerate somewhat higher query times on larger collections
Between MariaDB and PostgreSQL, the better choice will usually depend more on your existing infrastructure, team familiarity, and surrounding application requirements than on benchmark results alone.
Sparse Search at Scale
The benchmark data suggests that the main performance challenge for SQL backends at scale is sparse search over large collections. Dense vector search remains relatively fast across backends, while sparse ranking becomes the dominant source of additional latency as corpora grow. This does not make SQL unusable, but it does mean specialized vector engines retain an advantage once workloads become both large and sparse-heavy.
Final Thoughts
The choice between Qdrant and SQL backends isn't purely about performance—it's about trade-offs:
- Qdrant delivers consistently excellent performance with minimal tuning, but requires adding a new database to your infrastructure
- SQL backends (MariaDB/PostgreSQL) leverage existing infrastructure and expertise, while remaining viable for many real-world search workloads
For small to medium datasets, the performance differences are modest enough that operational considerations can easily outweigh raw speed. For larger datasets, Qdrant's latency advantage becomes clear, but the results also show that SQL backends remain practical if your workload can tolerate somewhat higher query times.
The good news: Amgix's abstraction layer means you can start with what you have (your existing SQL database) and migrate to Qdrant later if performance demands it—without changing your application code.
-
nDCG@k (normalized Discounted Cumulative Gain at k): A metric that measures the quality of ranking results. It considers both the relevance of retrieved documents and their position in the result list. A perfect ranking would have an nDCG of 1.0. Higher values indicate better search effectiveness. ↩↩↩↩
-
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. Thakur et al., 2021. https://arxiv.org/abs/2104.08663 ↩
-
P50 (50th percentile latency): The median query latency, meaning 50% of queries complete faster than this time and 50% take longer. This represents the typical user experience. ↩↩↩↩
-
P95 (95th percentile latency): The latency threshold under which 95% of queries complete. This metric captures the experience of the slowest 5% of queries, helping identify worst-case performance scenarios. ↩↩↩